


Mô hình và phản mô hình (2)
Mô hình, các phạm trù và sự cần thiết của tạo nghĩa

Ở bài trước tôi đã đưa ra vài ví dụ về việc mô hình, do bàn tay và khối óc con người tạo nên (thiết lập các phương trình toán học) không nhất thiết phải trỏ đến sự thật tuyệt đối. Tức là mọi mô hình được tạo ra đều bao hàm một sự xấp xỉ. Vào thời điểm một mô hình được cộng đồng khoa học — hoặc, chẳng hạn, một nhóm mainstream trong giới kinh tế học — thống nhất coi là nó có thể sử dụng được, sự xấp xỉ ấy luôn luôn vô cùng nhỏ, và sự lệch chuẩn để có thể gọi là sai khó có thể đong đếm bằng mắt thường.
Sự lệch ấy thường có thể được “đong đếm” dựa vào mối tương quan giữa các giá trị.

Mối tương quan (correlation) là sợi dây dò cơ bản trong làm khoa học thuần túy với nền tảng mô hình, hiểu theo nghĩa: quy trình đặt ra giả thuyết (hypothesis), thu thập số liệu, làm thử nghiệm, lại thu thập số liệu, và đánh giá giả thuyết có đúng hay không, đánh giá lại mô hình có phù hợp hay không, và từ đó, nếu cần, đặt ra lý thuyết. Mối tương quan không nói lên quan hệ nguyên nhân-kết quả. Có một ví dụ kinh điển là: khi trời nắng thì tôi ăn kem, khi trời nắng da tôi cũng bị cháy nắng, vậy là có mối tương quan giữa mức độ ăn kem và mức độ cháy nắng nhưng không có nghĩa vì tôi ăn kem nên da tôi cháy nắng.
Tính xấp xỉ của mô hình
Không khó để tìm một phương trình toán học bao hàm sự xấp xỉ, và sự xấp xỉ ấy có thể vô cùng nhỏ (dưới sự đo đạc mắt thường), cũng có thể kha kha lớn (nhìn từ góc độ của máy tính hiện đại). Dưới đây là phương trình trạng thái khí lý tưởng (ideal gas law):
 | Khan Academy")
với p là áp suất khối khí, V là thể tích, n là số mol khối khí, R là hằng số khí, T là nhiệt độ khối khí.
Trong hóa học và vật lý có khá nhiều định luật đi kèm với chữ “lý tưởng”: phải ở trạng thái lý tưởng của sự vật thì phương trình ấy mới thực sự chính xác. Cũng như với “ideal gas law” nói trên, định luật này không đúng với bất kỳ khí thực nào; nó cung cấp một giá trị gần đúng và sự xấp xỉ của nó (dù ít hay nhiều) là hữu ích trong việc đưa ra một góc nhìn vật lý về hoạt động của các phân tử khí. Cách chúng ta đặt ra phương trình cho một định luật (có hai vế và dấu bằng ở giữa, nếu đổi vế ta có sự tương quan khác giữa các biến) là sự mô phỏng cách ta nhìn và ta nghĩ về sự vật, theo một cách cấu trúc.
Bản đồ cũng có chức năng tương tự. Mặc dù mọi bản đồ đều là xấp xỉ, nhưng bản đồ chính là sự mô phỏng cách ta hình dung về không gian, về thế giới, và về vị trí ta đang ở.
George E. P. Box, nhà thống kê người Anh, được cho là nhân vật mở ra cuộc tranh luận rằng, liệu mọi mô hình có phải đều sai hay không (“All models are wrong, but some are useful”). Ông là người lấy ví dụ về định luật trạng thái khí lý tưởng và cho rằng, đối với một mô hình như vậy không cần phải đặt câu hỏi "Mô hình có đúng không?". Nếu "sự thật" là sự thật tuyệt đối và toàn bộ thì câu trả lời là "Không". Thay vào đó ,câu hỏi duy nhất cần được quan tâm là "Mô hình có sáng tỏ và hữu ích không?". ("Is the model illuminating and useful?")
Google và phản-mô hình
Khi ta tìm hiểu về corporate mission của Google, ta sẽ thấy những dòng sau hiện lên đầu tiên.
Google’s mission is to organize the world’s information and make it universally accessible and useful.
“Tổ chức” thông tin của thế giới, ở đây, bao hàm sự “trình bày”, vì nhiệm vụ của Google không chỉ là tổ chức mà còn đưa những thông tin ấy đến với nhân loại phổ quát và làm cho chúng hữu ích.
Chúng ta có ba từ khóa sau: organize, accessible và useful.
Sau hai mươi năm sử dụng các công cụ của Google gần như hàng ngày, với cá nhân tôi, nhiệm vụ ấy của Google coi như đã đạt được. “Coi như” chứ không phải là “hoàn toàn” hay “tuyêt đối” vì cả ba tác vụ organize, (make it) accessible và useful cần được hiểu theo nghĩa cố kết. Sự “hữu ích” ấy dành cho ai? Nếu là dành cho mọi người dùng của Google thì nhiệm vụ ấy coi như đã đạt được. Và với người dùng của Google, sự trình bày thông tin và sự thể hiện thế giới là theo cách của Google, chúng ta đâu có lựa chọn khác?
Thử lấy ví dụ từ công cụ phổ biến là Google Translate. Tôi dịch dòng mission từ Google tiếng Đức sang tiếng Việt.
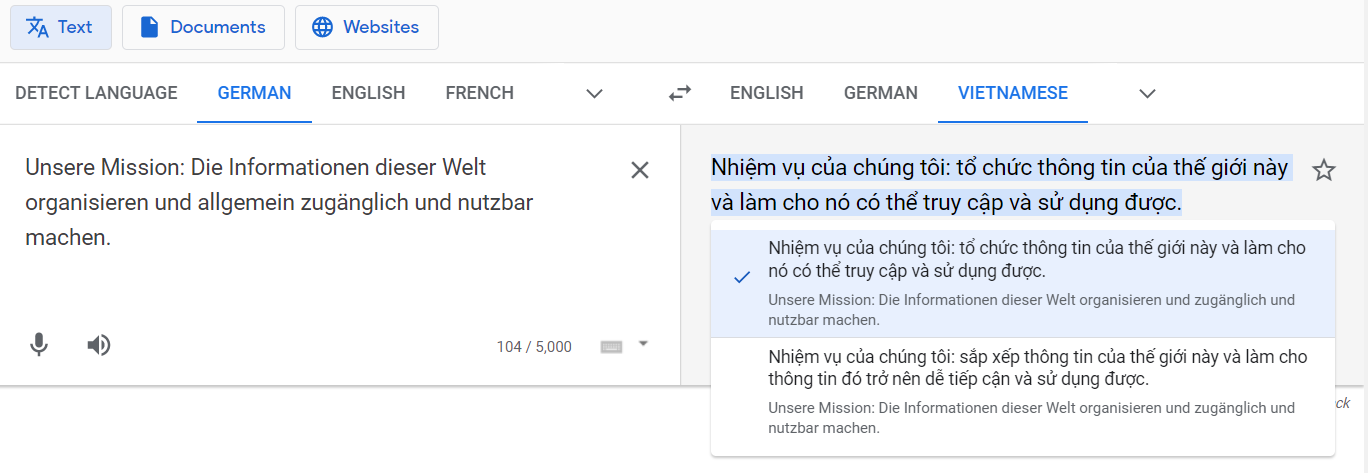
Google đã “đọc hiểu” được sự trình bày phổ quát tới mức ở ô tiếng Việt đưa cho chúng ta hai lựa chọn: lựa chọn thứ nhất dùng từ “nó”, lựa chọn thứ hai trỏ từ “nó” tới đúng chỗ “thông tin đó”.1
Ta biết rằng Google không thuê đội ngũ dịch giả chuyên nghiệp để dịch từng câu hay xây dựng nên Google Translate, mà họ thu thập một khối dữ liệu lớn các corpus của những ngôn ngữ khác nhau và dùng “máy học” (machine learning) xây dựng mối dây tương quan giữa các từ, giữa các cụm từ, giữa các khối nghĩa. Máy tính dĩ nhiên không học theo cách mà một người vẫn làm. “Máy học” sử dụng một lượng lớn dữ liệu để thực hiện các tác vụ (như spelling, nối các cụm từ, các khối nghĩa) bằng cách học từ các ví dụ.
Ở câu dịch phía trên, ta nhận ra rằng Google không chỉ giải quyết tác vụ rất nhanh (vài phần nghìn giây?) mà còn đưa cho người dùng hai lựa chọn. Cách làm này rất giống với A/B testing dùng trong marketing hay nghiên cứu người dùng: hệ thống đưa ra nhiều lựa chọn đối ngẫu, hoặc A hoặc B, và sau khi kiểm kê một lượng câu trả lời đủ lớn, người thiết kế hệ thống có thể phân tích được cách làm nào là hữu ích với người dùng.
Thời đại số và sức mạnh thuật toán
Cách dùng dữ liệu lớn để giải quyết các tác vụ về sắp xếp thông tin — Google dùng từ “thông tin” chứ không gọi đó là “tri thức” — báo hiệu cho sự phụ thuộc không thể tránh khỏi của con người vào máy tính. Hay tôi hay nói là “thời đại số”.
Tùy vào cách nhìn, thời đại số có thể vô cùng hữu ích. Thời đại số đem lại cho chúng ta nguồn thông tin “phổ quát” trong tích tắc; ngày xưa ta phải mất nhiều giờ hoặc nhiều ngày lục lọi trong thư viện. Thời đại số cho chúng ta, bất kể ai, quyền tiếp cận và phán xét thông tin; ngày xưa ta phải là ai đấy, ta phải mất công và nhiều khi lạy lục, mới có thể làm thẻ thư viện để được ngồi trong Thư viện khoa học tổng hợp.
Giai thoại kể rằng trong số những người xây dựng Google Translate cho ngôn ngữ tiếng Trung, không có người nào nói tiếng Trung nhuần nhuyễn.2 Họ chỉ cần biết cách lập trình cho máy học.
Chris Anderson, biên tập viên của Nature và Science sau đó nhảy sang Wired, là người đề xướng quan điểm “the end of theory”: lý thuyết đã cáo chung vì sự chi phối của dữ liệu lớn đến cách chúng ta đọc hiểu vấn đề và cách chúng ta xây dựng tri thức.

Anderson gọi thời đại số là “Petabyte Age” (một petabyte bằng khoảng một tỉ megabyte). Lập luận của Anderson có thể hiểu như sau: với sức mạnh của thuật toán và dữ liệu lớn, mọi phạm trù đều là khoảng xám, sẽ không có cái gọi là cái nồi/cái chảo/chảo rán/ghế bàn bar/phụ nữ trung niên làm văn phòng etc., mọi phạm trù sẽ cùng lúc biến đổi và thành hình cùng lúc với thuật toán chạy thường hằng. Để nắm được sự vật và hiện tượng, ta không nhất thiết cần tạo ra tri thức. Cũng như để dịch văn bản, Google không cần phải học cách dịch.
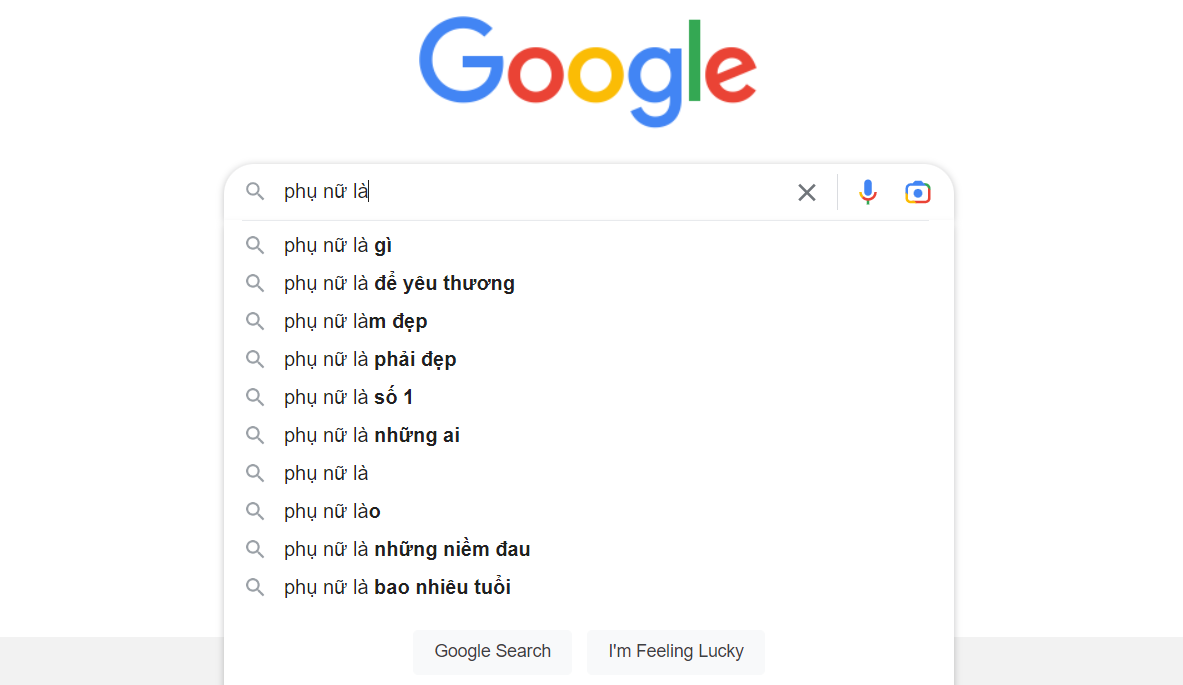
Như khi chúng ta hỏi “Phụ nữ là…”, Google sẽ đưa ra các chỉ dẫn dựa vào mức độ hiện diện của ý niệm đó trên thế giới web. Google không cần tìm ra chân lý, cái Google cần là tổ chức thông tin. Vì việc tìm ra chân lý không phải chủ chốt trong các tác vụ của Google cũng như máy học, cách con người ta trước nay vẫn truy nguyên chân lý dựa vào xây dựng mô hình sẽ trở nên lỗi thời.
Từ đó có hai hệ quả.
Một là, nếu lấy lý thuyết là cái sau cùng người ta cần hướng tới sau một chuỗi thử sai, lý thuyết như là tấm gương soi của hiện thực (người làm khoa học là người tạo ra và chỉnh sửa tấm gương ấy) thì cái nhìn phản-mô hình cũng đồng nghĩa với với sự chấm hết của lý thuyết; vì suy cho cùng, lý thuyết không còn vai trò gì nữa; mọi lý thuyết đều chỉ là phiên phiến.
Hai là cách ta suy nghĩ (thinking). Ta sẽ không cần tới suy nghĩ nữa vì suy cho cùng suy nghĩ sẽ chỉ là một dây các tác vụ tự động (bằng thuật toán) được chắp ghép lại. Suy nghĩ tự động khiến cho tri thức bị cào bằng và mất đi ý nghĩa nội sinh (có tri thức để làm gì khi tri thức ấy không phục vụ cho một nỗi đau đáu đến từ chính tinh thần ta?). Và từ góc nhìn biện chứng của Hegel (phép biện chứng nông nô/chủ nô), tri thức sinh ra thiếu nhất quán sẽ khiến cuộc đời ta là cuộc đời của kẻ lệ thuộc.
Tạm khép lại, tôi không đồng tình với cách nhìn của Anderson. Anderson có thể coi là “computer evangelist”, tức là nhìn máy tính như yếu tố định hình cuộc sống và hành vi xã hội của con người, và nó có sức mạnh làm được như thế. Còn tôi lại khá dè chừng với vai trò “dân chủ hóa” của máy tính. Được chạm vào, được sử dụng và thao túng một cổ máy từng là ước mơ của những con người xa xưa.3 Song thời đại số tạo ra những thay đổi liên tục và nhanh chóng khiến phần đông chúng ta không níu lại được “cái đã qua”, không tua lại được những “cái cũ”. Thời đại số làm cho mỗi người chúng ta phải tất tả chạy đua trong cuộc đua mà ta, đôi khi không nhận ra, rõ ràng là người thua cuộc.
Trước khi nói về sự cần thiết của lý thuyết, tôi sẽ còn trở lại câu hỏi: Liệu mô hình có còn cần thiết nữa không, vào thời đại số? Cùng với đó là, liệu các phạm trù và phép phân loại có còn cần thiết?
Dĩ nhiên là có chứ. Một mặt, các phạm trù, sự đa dạng và cái khác là nguồn kích thích cho chúng ta suy nghĩ; suy nghĩ và tạo ra ý nghĩa là lý do để tồn tại. Mặt khác, mô hình và các phạm trù là địa hạt tự chủ của con người, là chứng thư nói lên rằng tri thức được tạo ra là cố kết và hành trình tạo ra nó là nhất quán, và con người vì thế không bị lệ thuộc vào tác nhân nào. Con người vốn dĩ là loài vật mang tính chính trị và vì thế không ngừng bất tuân. Con người bất tuân ngay từ trong hình hài nguyên thủy nhất của ý nghĩ.4
Hóa ra Google cũng phần nào đồng tình với tôi đấy chứ. Tôi từng coi “nó” là từ xấu nhất trong tiếng Việt.
Giai thoại này được cho là của Peter Norvig, từng là giám đốc nghiên cứu của Google. Một trong các nguồn, Kevin Kelly, người đồng sáng lập tạp chí Wired, trong bài “The Google Way of Science” kể:
as Peter Norvig, head of research at Google, once boasted to me, “Not one person who worked on the Chinese translator spoke Chinese.”
Các nhà viết kịch cổ đại có một trick là Deus ex machina. Trong máy có Chúa. Máy, cũng như Chúa, tạo ra bước ngoặt. Cũng như trong một cái búng tay, Bụt hiện ra và cứu kẻ bị đày đọa.
Nghe có vẻ không logic, nhưng bất tuân chính là điều kiện để có đạo đức. Bằng chứng thời thượng nhất chính là vũ khí drone. Không có sự bất tuân, con người sẽ chỉ sử dụng drone như cỗ máy được lập trình bài bản, và được chạy gần như hoàn hảo. Lỗi của máy, dù chí tử, sẽ chỉ là lỗi cài đặt. Khi lỗi là ở máy chứ không phải con người (nếu drone giết nhầm), sẽ không có khái niệm người lính mà chỉ có lập trình viên hay điều hành viên, và việc huy động drone theo đó là vi phạm luật chiến tranh quy ước. (Ủa, không có người lính thực sự thì có được xem là chiến tranh hay không?)