


Không gian và ngôn ngữ (2)
Tính lòng vòng của ngôn ngữ

Trong bài Không gian và ngôn ngữ (1) lần trước, tôi có giới thiệu qua về hệ thống phân loại hai phần của Linnaeus. Qua mô hình này, ta có thể thấy ngôn ngữ, cụ thể hơn là tên riêng và danh từ, có thể tuyến tính và được sắp đặt một cách tôn ti như thế nào. Chính vì có thể gò ngôn ngữ (đặc biệt là ngôn ngữ viết) trở nên tôn ti và tuyến tính, người có thẩm quyền biến nó trở nên trực quan và tiện lợi. Cách phân loại tiêu chuẩn có thể thấy ở bất cứ đâu, từ bao bì trên vỏ hộp sản phẩm, giá sách trong thư viện, cho đến những cuộc tranh cãi về chính tả.
“Giang tay” hay “dang tay” mới đúng? Chúng ta được dạy rằng “dang tay” là đúng. Hôm bữa trao đổi với một bạn proofreader, bạn này bảo tôi dùng từ “cross-sectorial” (trong ngữ cảnh đang nói về data management) là chưa chuẩn, mà phải là “cross-sectoral”. Thật ra không ai có thể đoan chắc về điều này (hiện tượng ngôn ngữ chạy “lòng vòng” lát nữa tôi sẽ nói), nhưng theo bạn ấy kiểm tra trên Google scholar thì “cross-sectoral” được dùng 140k lần còn “cross-sectorial” chỉ có 15k lần. Thỉnh thoảng khi tôi lăn tăn về chính tả hay cách viết chính tắc một từ nào đó, chẳng hạn “A Rập” hay “Ả Rập”, hay “A-rập”, tôi vẫn tra Google xem từng cách viết khác nhau được bao nhiêu hit.
Ở đây ta quan tâm nhiều tới tôn ti hơn là sự đúng sai. Các mô hình ngôn ngữ lớn (LLM) dùng phương pháp tự hồi quy (autoregressive) cũng vận hành dựa theo quy tắc về tôn ti như vậy. Tôn ti quy định thứ tự. Có thứ tự, sẽ sinh ra xác suất gần đúng. Xác suất giải quyết vấn đề phỏng đoán ở bậc đơn giản. (Các mô hình tự hồi quy dùng các từ trước đó để dự đoán từ tiếp theo trong chuỗi. ChatGPT là điển hình của phương pháp tự hồi quy. Công cụ này sử dụng kiến trúc Transformer, vốn phù hợp để xử lý các chuỗi văn bản dài.)
***
Trong podcast mới đây của Lex Fridman, Yann Lecun, chuyên gia về AI ở Meta diễn đạt lại khá súc tích các chỉ trích của ông trước đây, rằng LLM còn lâu mới đạt trí thông minh của con người. Ông dẫn ra nghịch lý kinh điển (Moravec's Paradox) của nhà tiên phong robot học gốc Áo Hans Moravec: tại sao máy tính giỏi những việc phức tạp, tinh vi cấp độ cao như chơi cờ vua, giải toán tích phân, trong khi những kỹ năng đơn giản đời thường như lái xe, cầm nắm đồ vật thì lại khó? Các LLM, như Chat GPT-4, giờ có thể vượt qua những kỳ thi luật, nhưng chưa thể học cách dọn bàn ăn và xếp bát đĩa vào máy rửa chén như một đứa trẻ 10 tuổi chỉ sau một lần hướng dẫn.

Lý do, Lecun đưa ra, là các LLM chưa thể xây dựng được mô hình thống nhất về thế giới - một cách riêng để nó nhìn thế giới như là cách một đứa trẻ nhìn thế giới. Một đứa trẻ ba tuổi có thể không nói được quá nhiều từ, nhưng nó đã dành khá nhiều thời gian trong lúc mình không ngủ (tầm 12 tiếng mỗi ngày) tương tác với thế giới xung quanh qua các giác quan. Đứa trẻ cầm thức ăn lên và bỏ vào mồm, hay nó cầm ly nước lên, nhìn một lúc và thản nhiên đổ ly nước xuống đất, như một cách học (tôi đã được chứng kiến tận mắt rồi hehe).
Hoặc, khi tôi muốn nói “ba tuổi” tôi sẽ viết “ba”, còn khi nói “10 tuổi” tôi sẽ viết “10”, vì trong mô hình thế giới của tôi, từ 10 trở nên, viết số “nhìn được” hơn.
***
Khi coi việc bỉ bôi nói ngọng là biểu hiện của “elitism ngôn ngữ”, tôi có đưa ra quan điểm rằng chúng ta hãy coi ngôn ngữ là thuộc về một phần thân thể một ai đó:
Bởi ngôn ngữ là tiếng của con người, tiếng nói phát ra từ miệng, lời có thể đến từ suy nghĩ hoặc bật ra không cần suy nghĩ, nhưng tất cả yếu tố ấy là một phần của cơ thể.
Việc đến từ cơ thể chính là yếu tố làm cho ngôn ngữ, tiếng nói, có sự khác biệt giữa người với người.
Một người, như là một cá thể có ý thức, họ sẽ nói làm sao để “nghe được”. Việc “nói” và “nghe được” ấy chính là một mô hình thống nhất về thế giới, một cách riêng họ nhìn thế giới. Chuyện người khác nhìn thế giới thế nào, chúng ta không nên gò vào những phạm trù đúng-sai.
Một khi hiểu điều này, chúng ta có thể giải mã được rất nhiều hiện tượng khác.
***
Quay lại câu hỏi ở trên: “Giang tay” hay “dang tay” mới đúng? Mặc dầu đã đụng phải chúng từ những giờ học môn ngữ pháp hồi lớp 5 (ngại quá, khi đó tôi còn học đội tuyển để đi thi HSG cấp tỉnh), nhưng hầu hết những lần gặp lại cặp từ này về sau, tôi đều phải tra Google cho chắc. Vì khi phát âm lên, cả hai từ này đều… nghe được. Chúng khác với kiểu, “súc tiến” hay “xúc tiến” (dĩ nhiên “xúc tiến” là đúng). Một khi cả hai từ đều nghe được thì lời giải của tôi là: mọi thứ chưa ngã ngũ, chúng ta không chắc được từ nào Đúng, và chúng ta cũng không chắc được, từ nào mới là có trước.
Cũng giống như “Tân Sơn Nhất” hay “Tân Sơn Nhứt”, từ nào có trước?
Thế có bạn sẽ bảo, cứ theo từ điển mà táng thôi, cần gì quan trọng chuyện từ nào có trước. Thế nhưng từ điển (hay ở Pháp còn có cả bộ phận của Viện Hàn lâm nêu quan điểm chính thức về những vấn đề chính tả, từ mới hay cách dùng từ, lúc nào rỗi tôi hay đọc ở đây) cũng chỉ là sản phẩm của một lớp học giả, áp đặt ý hệ về ngôn ngữ, hay cách nhìn thế giới của họ lên một lớp người khác, là những người dùng từ điển, hay những ai coi trọng thẩm quyền của quyển từ điển đó. Như vậy đâu thể thiếu thiên kiến?
Chữ “normal” (bình thường) còn có nghĩa là “chuẩn tắc”; bạn nào học thống kê còn nhớ phân phối chuẩn chứ?
Tôi còn nhớ đọc quyển Từ điển Triết học của NXB Sự thật in năm 1976 (quyển này in đến 30.180 cuốn), trong mục từ về Henri Bergson, họ gọi ông là “bọn duy tâm”. Tôi tự hỏi “duy tâm” là cái của khỉ gì nhỉ? Tra một hồi thì mới biết “duy tâm” là dịch từ “Idealism”, thật ra đâu có đúng; mà khi người ta dùng từ “duy tâm” như một khái niệm để đối lập với “duy vật” (materialism), thì theo cách nhìn thời bây giờ, thật khập khiễng.

Cũng như khi ai đó nói hoặc viết, hoặc đề biển hiệu “Tân Sơn Nhứt”, bạn chụp lại đăng lên tường cá nhân rồi chỉ trích người ta viết sai chính tả… Chơi như vậy đâu có được?
***
Cách đây mấy hôm tờ báo lá cải ở Anh, Daily Mail giật tít:
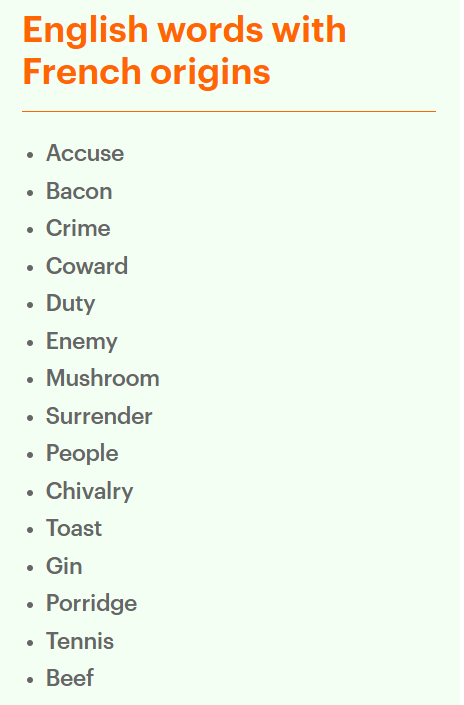
Chuyện như thế này: Bernard Cerquiglini, nhà ngôn ngữ học thuộc Viện Hàn lâm Bỉ, từng gia nhập nhóm Oulipo, ra mắt cuốn sách tên là La langue anglaise n'existe pas, từ NXB Gallimard uy tín. Theo ông, tiếng Anh vay mượn rất nhiều từ tiếng Pháp, lên đến 40% (khoảng 80.000 từ). Sau cuộc xâm lược Anh của người Norman (1066), tiếng Pháp thống trị nước Anh, ảnh hưởng nhiều đến tiếng Anh. Nhiều từ vay mượn như: butler (bouteiller - quản lý rượu), vintage (vendanges - mùa thu hoạch nho), coward (couard - hèn nhát), tennis (tenez - cầm lấy), enemy (enemi - kẻ thù), stew (estuver - hấp), pudding (boudin)... đều có nguồn gốc Pháp.
Cerquiglini mô tả hiện tượng này như sau: nhiều từ tiếng Anh có gốc Pháp, được vay mượn, biến đổi, rồi quay lại tiếng Pháp với phiên bản tiếng Anh. Và ông cho rằng, nếu nói đúng ra, một cách một trọng, thì phải phát âm những từ gốc Pháp này theo kiểu Pháp.
Việc ngôn ngữ biến đổi “lòng vòng” như vậy không có gì bất ngờ. Trong tiếng Việt có không ít trường hợp cùng một từ gốc nhưng bị biến đổi tùy theo vùng miền, như “Hoa” và “Huê”, “Võ” hay “Vũ”, “Tùng” hay “Tòng”, “mùng tơi” hay “mồng tơi”. Nhìn ngôn ngữ theo cách phi tuyến tính như vậy sẽ giúp ta giải thiêng được hiện tượng từ “Hán Việt”. Người Việt gặp một vấn đề rất khó giải quyết, gần như bất khả, là phán đoán xem từ nào gốc Hán và từ nào không phải, từ nào Hán Việt và từ nào thuần Việt. Tôi cho rằng khái niệm từ “Hán Việt” cũng chỉ là huyền thoại, vì vài lý do tôi đã chỉ ra ở trên:
Ta không biết chắc được từ nào có trước, và đôi khi đáp án lại hoàn toàn ngược lại với những gì chúng ta nghĩ là mình biết
Ngôn ngữ biến đổi lòng vòng, cũng có “nhập vai” và “thoát vai”, có “thoát vai” nhưng mà thoát chưa hết. Chẳng hạn sẽ có trường hợp thế này: một từ tồn tại trong tiếng Việt cổ, người ta thấy na ná với cách phát âm một từ chữ Hán, rồi lấy cách viết từ Hán đó áp cho từ Việt này, rồi theo thời gian nghĩa của từ Việt này cũng nhích nhích dần sang nghĩa của từ Hán đó, trong khi nghĩa từ Hán đó trong ngôn ngữ Hán cũng thay đổi theo hướng khác. Na ná như ví dụ về từ pudding ở trên; nếu nghiêng về giả thiết từ này xuất phát từ tiếng Pháp “boudin”, thì nghĩa “boudin” trong tiếng Pháp cổ là "sausage".
Cũng một từ gốc, nếu tiến về phương Bắc sẽ biển đổi khác, tiến về phương Nam biến đổi khác (do vấn đề phong khí, thời tiết)
Là một từ được “coi” là gốc Hán Việt, nhưng khi bị Việt hóa, nó đã mang nét mang mác khác rồi, và nó trở thành một từ độc lập (ví dụ “an nhiên” và “an yên”).
Thứ mà một số học giả trước đây gọi là quy tắc, thật ra là chẳng có quy tắc nào cả; hoặc là, chúng mang một quy tắc khác, chỉ vì người ta nhóm sai cách (từ “Hán Việt” và “thuần Việt” theo tôi là nhóm sai cách).
Bài tới, tôi sẽ đi sâu vào hiện tượng “lòng vòng” của ngôn ngữ, và khai thác một nhóm từ, một “phổ” đặt tên thuộc vào hàng nhàm chán nhất mà bạn có thể tưởng tượng được: các hợp chất và chất phụ gia thực phẩm.
Chào mừng các bạn đến với các hiện tượng nhàm chán của ngôn ngữ!
Đây là quà tặng từ Gemini cho các bạn đọc đã subscribe.

Còn những ai chưa subscribe thì thân ái mời.